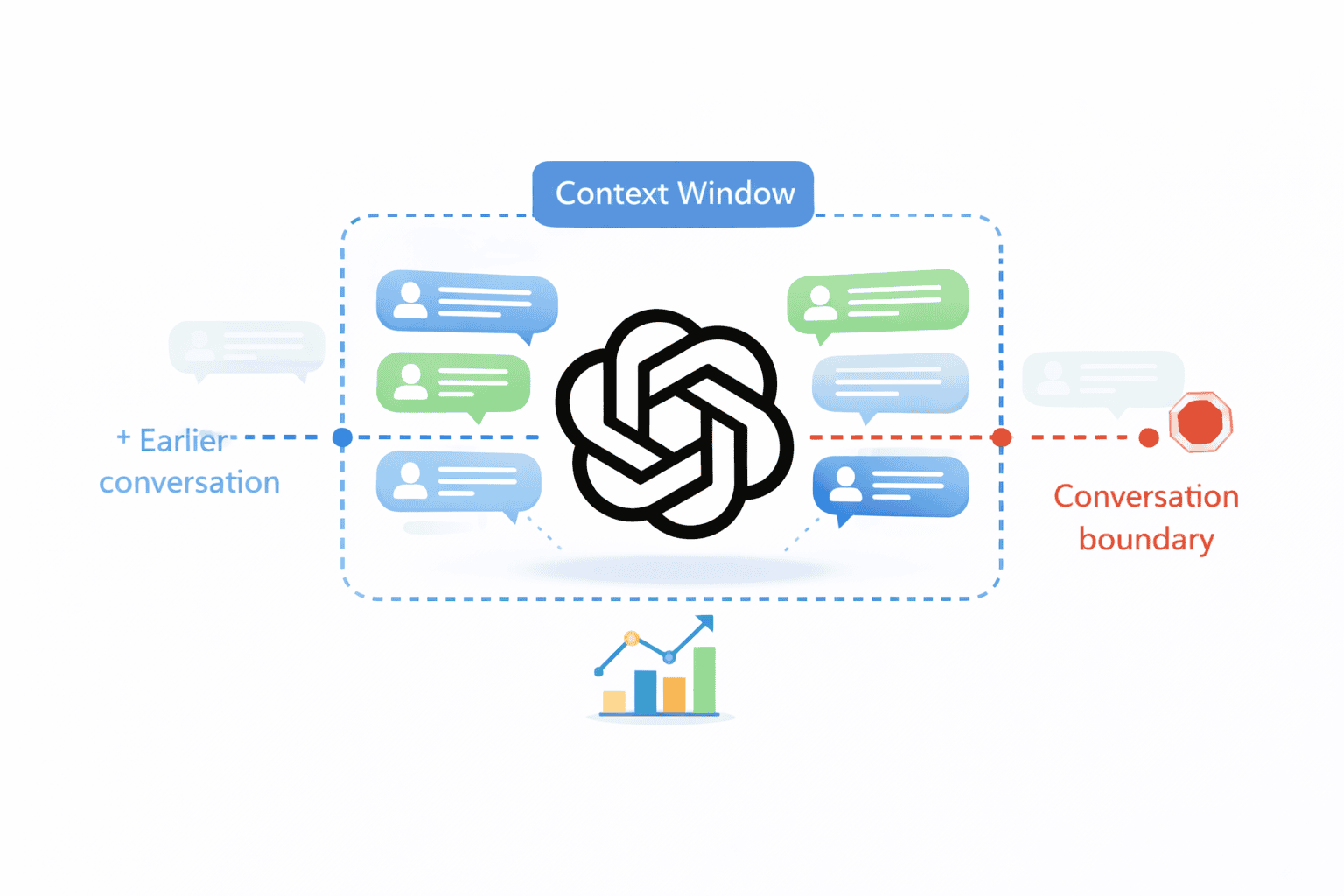
Context Window في ChatGPT هي مقدار النص أو المحادثة الذي يستطيع النموذج معالجته وتذكّره في آنٍ واحد. ببساطة، إنه حد “الذاكرة” القصيرة المدى للنموذج داخل المحادثة الحالية. أي معلومات أو رسائل تتجاوز هذا الحد لن يتمكن ChatGPT من استخدامها مباشرةً عند توليد الردود الجديدة، مما يفسّر لماذا قد ينسى التفاصيل القديمة أثناء المحادثات الطويلة.
ما المقصود بـ Context Window (نافذة السياق)؟
Context Window تعني حرفيًا “نافذة السياق”، وهي تحدد حجم النص الذي يمكن لنموذج الذكاء الاصطناعي (مثل ChatGPT) قراءته وأخذه بالاعتبار أثناء توليد الرد. فكر فيها كذاكرة مؤقتة أو مساحة عمل محدودة تمتد لعدد معين من الكلمات أو الرموز (Tokens). النموذج يركز فقط على المحتوى الموجود ضمن هذه النافذة عند إنتاج الجواب؛ أي أنه ينظر إلى أحدث ما قيل في حدود هذا الحجم ولا “يرى” ما يقع خارجها. يتم قياس حجم السياق بالرموز النصية (Tokens)، وهي وحدات نصية يستخدمها النموذج لمعالجة اللغة. وغالبًا ما يُذكر كقاعدة تقريبية أن الرمز الواحد يعادل نحو 4 أحرف أو حوالي 0.75 كلمة في اللغة الإنجليزية، لكن هذه القاعدة قد تختلف في اللغات الأخرى.
أما في اللغات الأخرى مثل العربية، فقد يختلف عدد الرموز بالنسبة لعدد الأحرف أو الكلمات، وغالبًا ما ينتج النص عددًا أكبر من الرموز مقارنة بالإنجليزية. كما أن تقدير الرموز بناءً على عدد الأحرف (مثل characters ÷ 4) يكون مجرد تقريب، وقد يصبح أقل دقة عند التعامل مع الملفات الكبيرة أو الصور أو الأدوات البرمجية. لذلك يستخدم المطورون عادة أدوات مخصصة أو واجهات برمجية لحساب عدد الرموز بدقة أكبر عند الحاجة. على سبيل المثال، عندما أعلنت OpenAI عن نموذج GPT-4 Turbo، ذكرت أن سعته السياقية حوالي 128 ألف رمز – أي ما يزيد عن 300 صفحة من النص يمكن وضعها في مطالبة واحدة! هذا تطور كبير مقارنةً بالإصدارات الأقدم من نماذج GPT. فمثلًا كانت بعض الإصدارات السابقة مثل GPT-3.5 تتعامل مع نحو 4 آلاف رمز فقط، ثم ظهرت إصدارات لاحقة بسياق أكبر مثل GPT-3.5 Turbo بسعة تقارب 16 ألف رمز وGPT-4 بسياق يصل إلى 8 آلاف أو 32 ألف رمز. تجدر الإشارة إلى أن هذه الأرقام تمثل تطورًا تاريخيًا في النماذج السابقة، وليست بالضرورة حدود النماذج المستخدمة في ChatGPT حاليًا. ببساطة، Context Window هو الحد الأقصى لما يستطيع ChatGPT استيعابه من حديثك وتعليماتك في أي لحظة ضمن المحادثة الحالية.
الفرق بين السياق (Context) والذاكرة (Memory) وسجل المحادثة
من المهم التمييز بين ثلاثة مصطلحات قد تختلط على المستخدمين: السياق Context، والذاكرة Memory، وسجل المحادثة Chat History.
- السياق هو ما شرحناه أعلاه: محتوى المحادثة (بما في ذلك كلامك وكلام الذكاء الاصطناعي والتوجيهات) الذي يكون نشطًا ضمن حدود نافذة السياق الحالية. هذا السياق هو وحده ما “يتذكره” النموذج أثناء توليد الرد. إنه ذاكرة مؤقتة قصيرة المدى للنموذج خلال المحادثة الراهنة.
- سجل المحادثة هو السجل الكامل الذي تراه محفوظًا في واجهة ChatGPT لجلسة الحوار – أي قائمة الرسائل المتبادلة منذ بدء المحادثة. هذا السجل قد يكون أطول بكثير من قدرة النموذج على استيعابه كاملًا. عمليًا، ChatGPT لا يطالع إلا الأجزاء الأخيرة من سجل المحادثة بما يتناسب مع حد السياق؛ أما الرسائل القديمة جدًا في نفس الجلسة فقد لا تدخل في حسابات النموذج إذا تجاوزت الحد. وجود الرسائل في واجهة التاريخ لا يعني أن النموذج يراها كلها، فهو ليس كالبشر يحتفظ بكل شيء قاله سابقًا.
- الذاكرة (Memory) في ChatGPT: تشير الذاكرة إلى مجموعة من الميزات التي تسمح للنموذج بالاحتفاظ ببعض المعلومات المفيدة عبر محادثات متعددة لتحسين التجربة الشخصية للمستخدم. وتنقسم هذه الذاكرة اليوم إلى نوعين رئيسيين: Saved Memories وReference Chat History. Saved Memories هي معلومات محددة قد يقوم ChatGPT بحفظها عنك — مثل تفضيلاتك أو معلومات متكررة في محادثاتك — وقد يتم حفظها أحيانًا تلقائيًا عندما يرى النظام أنها مفيدة للمحادثات المستقبلية، وليس فقط عندما تطلب منه حفظها صراحةً. أما Reference Chat History فهي ميزة تسمح للنظام بالرجوع إلى معلومات ذات صلة من محادثات سابقة لتحسين الردود في محادثات جديدة عند الحاجة. وعندما تكون هذه الميزات مفعّلة، يمكن لبعض هذه المعلومات أن تُدرج ضمن السياق الذي يستخدمه النموذج أثناء توليد الردود. وفي المقابل، إذا أراد المستخدم إجراء محادثة لا تستخدم أي ذكريات محفوظة أو تاريخ سابق، يمكنه استخدام Temporary Chat، وهي محادثة مؤقتة لا يتم فيها حفظ معلومات جديدة ولا استخدام الذكريات السابقة.
ملاحظة: كثيرًا ما يُساء فهم قدرة ChatGPT، فيظن البعض أنه يحتفظ بكل محادثاتك السابقة أو “يتعلم” منها تلقائيًا. الحقيقة أن النموذج لا يتذكر محادثات سابقة في جلسة جديدة ما لم تستخدم ميزة الذاكرة أو توفر له تلك المعلومات من جديد. وأيضًا، حتى داخل الجلسة الواحدة، قد ترى كامل السجل لكن النموذج قد نسي فعليًا أجزاء منه إن تجاوزت حد السياق.
كيف يقرأ ChatGPT سياق المحادثة والملفات المرفقة؟
عند استخدامك لـChatGPT، يقوم النظام في كل مرة ترسل فيها رسالة بتجميع سياق المحادثة الحالي وإرساله إلى نموذج الذكاء الاصطناعي لمعالجة رد جديد. عادةً يتضمن هذا السياق: تعليمات النظام (System messages) التي تحدد سلوك النموذج، ثم آخر عدد ممكن من الرسائل المتبادلة بينك وبين النموذج (بحيث لا يتجاوز المجموع حد الـContext Window). عند إرفاق ملفات في ChatGPT، لا تتم معالجة جميع أنواع الملفات بالطريقة نفسها. فطريقة قراءة الملف تعتمد على نوعه والأدوات المتاحة في الخطة المستخدمة. في بعض الحالات قد يتم إدراج جزء من النص مباشرةً داخل سياق المحادثة ليستخدمه النموذج أثناء توليد الرد. أما بقية المحتوى فقد يُخزَّن في فهرس بحث داخلي بحيث يستطيع النظام استرجاع الأجزاء ذات الصلة فقط عند الحاجة. تختلف طريقة المعالجة أيضًا حسب نوع الملف. النصوص والمستندات قد يُدرج جزء منها في السياق ويُستخدم الباقي عبر آلية استرجاع داخلي. أما الجداول والبيانات فغالبًا ما يتم تحليلها باستخدام أدوات مثل بيئة Python المدمجة لتحليل البيانات. يمكن لـChatGPT تحليل بعض أنواع ملفات PDF واستخراج النص منها، بينما قد تتوفر قدرات تحليل الصور أو الرسومات داخل ملفات PDF في بيئات أو خطط متقدمة مثل Enterprise. وفي بعض بيئات ChatGPT Enterprise قد يتم إدراج جزء كبير من محتوى المستند داخل السياق — يصل في بعض الحالات إلى عشرات الآلاف من الرموز — بينما يتم التعامل مع بقية المحتوى عبر آليات استرجاع داخلي. بينما يتم التعامل مع بقية النص عبر آلية الاسترجاع. أما من حيث حدود رفع الملفات، فيسمح ChatGPT حاليًا بتحميل ملفات يصل حجمها إلى نحو 512 ميغابايت لكل ملف، مع حد يصل إلى حوالي 2 مليون رمز للمستندات النصية. وعلى واجهة الويب يمكن — وفق تحديثات ChatGPT الأخيرة — إرفاق حتى 20 ملفًا في رسالة واحدة، وقد تختلف هذه الحدود حسب الخطة والتحديثات المستقبلية. كما توجد حدود استخدام عامة لرفع الملفات خلال فترة زمنية محددة تختلف حسب الخطة المستخدمة.
كيف يقرر ChatGPT أي أجزاء من المحادثة يدرجها في السياق؟ ذلك يحدث تلقائيًا بحسب الحاجة وحدود النموذج. بشكل افتراضي، يحاول النظام تضمين أحدث الرسائل التي تتسع ضمن الحد الأقصى للرموز. لنفترض أن الحد الأقصى 32 ألف رمز وكانت محادثتك أطول من ذلك؛ سيقوم ChatGPT عند توليد الرد التالي باستبعاد الرسائل الأقدم (من بداية المحادثة) إلى أن يصبح مجموع الرموز ضمن الحد المسموح. هكذا “ينزلق” نافذة السياق مع تقدم المحادثة: كلما أضفت رسائل جديدة وكان السياق ممتلئًا، يخرج أقدم محتوى منه. أما محتوى الملفات المرفقة فقد يُدرج جزء منه داخل السياق بينما يتم استرجاع بقية المحتوى عند الحاجة. إذا أرفقت ملفًا نصيًا كبيرًا جدًا يتجاوز القدرة، قد يعتذر ChatGPT بأنه لا يستطيع قراءته كاملًا. لا توجد معلومات رسمية توضح أن ChatGPT يقوم بتلخيص المحتوى القديم تلقائيًا عند امتلاء نافذة السياق، لذلك يُفترض عادةً أن الرسائل الأقدم يتم استبعادها ببساطة عندما يتجاوز السياق الحد المسموح. لكن هذا الأمر غير معلن رسميًا من OpenAI. لكل نموذج حد إجمالي مشترك للمدخلات والمخرجات، وإذا تجاوزته يجب تقليل المدخلات أو تقسيمها. وفي بعض ميزات ChatGPT، خصوصًا مع الملفات الكبيرة، قد تعتمد المنصة على الاسترجاع/البحث الداخلي بدل إدراج كل المحتوى حرفيًا داخل نافذة السياق.
لماذا ينسى ChatGPT أحيانًا أو يتجاهل جزءًا من المحادثة؟
يشتكي بعض المستخدمين من أن ChatGPT بدأ ينسى ما قيل سابقًا أو يُجيب بإجابات متناقضة في محادثة طويلة. السبب الرئيسي وراء ذلك هو محدودية نافذة السياق كما شرحنا. النموذج ليس لديه ذاكرة دائمة لكل ما قيل؛ بمجرد امتلاء النافذة بالحد الأقصى من الرموز، سيضطر للتخلي عن أقدم الأجزاء. بالتالي إذا طالت المحادثة جدًا، قد يفقد النموذج تفاصيل مهمة ذُكرت في البداية أو ينسى سياق السؤال الأصلي. هذا يفسّر لماذا قد تصبح الإجابات أقل دقة أو خارج الموضوع بعد عدد كبير من التفاعلات المستمرة.
لنضرب مثالًا عمليًا: لنفترض أنك في بداية المحادثة أخبرت ChatGPT بتفاصيل عن مشروعك أو تفضيلاتك الشخصية. ثم بعد عشرات الرسائل دخلتما في مواضيع فرعية. عندما تعود لتسأله عن أمر يرتبط بتلك التفاصيل الأولى، قد يبدو وكأنه لا يتذكرها. ليس ذلك تعطّلًا أو سوء فهم منه، بل لأن تلك المعلومات خرجت من نطاق السياق الذي يستخدمه حاليًا. النماذج ذات النافذة الصغيرة (القليلة الرموز) تعاني أكثر من هذه المشكلة؛ كانت الإصدارات الأقدم من GPT “تنسى” سياق المحادثة بسرعة نسبية. أما الآن مع تطور النماذج وازدياد سعة السياق، يمكن للمحادثات أن تمتد أطول قبل أن يبدأ النسيان. لكن حتى لو وصلت السعة لمئات الصفحات، فهي محدودة في النهاية. أي معلومات خارجها لن يتمكن النموذج من النظر إليها أثناء رده.
هناك أسباب أخرى قد تبدو وكأنها نسيان من ChatGPT لكنها تختلف عن مسألة السياق، نذكرها باختصار:
- إذا بدأت موضوعًا جديدًا تمامًا في نفس المحادثة دون توضيح، قد يخلط النموذج بينه وبين الموضوع السابق. الحل هنا عادةً بدء محادثة جديدة لموضوع جديد.
- إذا كان سؤالك غامضًا أو مليئًا بمعلومات كثيرة، قد يركز النموذج على أجزاء وينسى أجزاء لأنه لم يفهم أين التركيز. هذا ليس نسيان سياقي بل قصور في وضوح التعليمات.
- تمتلك نماذج ChatGPT ما يُعرف بتاريخ المعرفة (Knowledge Cutoff)، وهو التاريخ الذي توقفت عنده البيانات المستخدمة في تدريب النموذج. لكن من المهم ملاحظة أن هذا التاريخ ليس موحّدًا لكل النماذج، بل يختلف من نموذج إلى آخر حسب الإصدار. كما أن ChatGPT لم يعد يعتمد فقط على بيانات التدريب في كثير من الحالات. فبفضل ميزات مثل ChatGPT Search يمكن للنظام الوصول إلى معلومات حديثة من الويب وتقديمها مع روابط للمصادر. وفي بعض الحالات قد يقوم ChatGPT بالبحث تلقائيًا عندما يرى أن السؤال يحتاج معلومات أحدث من بيانات التدريب المتاحة.
بشكل عام، السبب الأشيع لتلاشي المعلومات من ردود ChatGPT خلال الحوار هو محدودية Context Window. النموذج قد يتناسى أجزاء من المحادثة عمداً لأنه لم يعد يمتلكها في ذاكرته المؤقتة خلال إنتاج الجواب. هذا أمر متوقع وطبيعي لكل نماذج اللغة الحالية، لذا من المهم للمستخدم إدراك الحدود والتخطيط للتعامل معها (سنذكر بعد قليل أفضل الممارسات).
ما هي حدود السياق الحالية في ChatGPT (وفق الخطط والنماذج)؟
تتطور سعة نافذة السياق مع تطور النماذج التي تشغّل ChatGPT. إليك نظرة عامة على الحدود الرسمية المعلنة حتى تاريخ آخر مراجعة للمقال في مختلف الخطط والأوضاع:
خطة ChatGPT المجانية (Free): في النسخ الحديثة من ChatGPT تُستخدم نماذج من سلسلة GPT-5.x مثل GPT-5.3 Instant وGPT-5.4 Thinking، وتختلف النماذج المتاحة حسب الخطة والإعدادات. ويبلغ الحد التقريبي لنافذة السياق في الوضع الافتراضي (Instant) عشرات الآلاف من الرموز (tokens)، وهو حجم يكفي لمعظم الاستخدامات اليومية مثل الأسئلة العامة والمحادثات القصيرة، لكنه قد يصبح محدودًا عند التعامل مع نصوص طويلة جدًا أو محادثات ممتدة.
الخطط المدفوعة في ChatGPT: تتيح الخطط المدفوعة الوصول إلى نماذج أسرع أو أوسع سياقًا، كما قد تتيح أوضاعًا إضافية مثل Thinking أو نماذج أكثر تقدمًا. تختلف حدود نافذة السياق في ChatGPT حسب النموذج والوضع المستخدم (مثل Instant أو Thinking) وكذلك حسب الخطة. في كثير من الحالات توفر الخطط المدفوعة نوافذ سياق أكبر من الخطة المجانية، ما يسمح بالتعامل مع نصوص أطول ومحادثات أكثر تعقيدًا. ومع ذلك، قد تتغير هذه الحدود بمرور الوقت مع تحديث النماذج، لذلك يُنصح بالرجوع إلى الصفحات الرسمية للنماذج لمعرفة الحدود الحالية بدقة. كما يجدر التنبيه إلى أن خطة Team التي كانت مستخدمة سابقًا تم تغيير اسمها رسميًا إلى Business منذ عام 2025.
النماذج المتخصصة وواجهات برمجة التطبيقات (API): من المهم التمييز بين حدود السياق داخل تطبيق ChatGPT وبين الحدود المتاحة في نماذج OpenAI عبر واجهة البرمجة (API) المخصصة للمطورين. في واجهة API يمكن لبعض النماذج الحديثة التعامل مع نوافذ سياق أكبر بكثير من تلك المستخدمة داخل تطبيق ChatGPT. ومع ذلك، فإن هذه الحدود تخص بيئة التطوير عبر API، ولا تعني أن مستخدم ChatGPT العادي يحصل على نافذة سياق بهذا الحجم داخل التطبيق نفسه. لذلك تختلف حدود السياق بين تطبيق ChatGPT للمستخدمين وبين النماذج المتاحة للمطورين عبر API.
وللتوضيح، الرمز (Token) هو وحدة نصية قد تمثل كلمة كاملة أو جزءًا من كلمة أو حتى علامة ترقيم، حسب طريقة تقسيم النص لدى النموذج. فمثلاً 100 ألف رمز قد توازي تقريبًا 75 ألف كلمة (نص بحجم رواية طويلة). لذا نافذة سياق 256k تسمح فعليًا بمدخلات بحجم كتاب كامل. بالطبع، التعامل مع هذا الحجم عمليًا ما زال يتطلب تخطيطًا (من حيث التكلفة والوقت)، لكن النموذج مدرب على التعامل مع هكذا سياقات عند الحاجة. في واجهة ChatGPT، سترى عادةً تنبيهًا أو منعًا إذا حاولت تجاوز حد السياق – مثلاً رسالة خطأ تقول “المحادثة طويلة جدًا، ابدأ محادثة جديدة” إذا تجاوز عدد الرموز الحد المسموح. عمومًا، كقاعدة: كل خطة أو نموذج تأتي مع حد أقصى لعدد الرموز في السياق، وتلك الحدود أكبر في الخطط المدفوعة والأحدث.
تلميح: إذا كنت غير متأكد من مقدار ما تبقى في نافذة السياق، يمكنك أن تطلب من ChatGPT تلخيص ما يتذكره حتى اللحظة أو تعداد النقاط التي لا يزال على علم بها. هذه ليست طريقة مضمونة 100%، لكنها أحيانًا تعطيك مؤشرًا عما يوجد حاليًا في ذاكرة النموذج ضمن الحدود.
ماذا يحدث عندما تكبر المحادثة أو يطول الملف عن الحد؟
عندما تقترب المحادثة من حد Context Window، يبدأ النموذج بإهمال الأجزاء الأقدم كما أسلفنا. في البداية قد لا تلاحظ أي فرق لأن المعلومات الأساسية ربما لا تزال ضمن النافذة. لكن مع استمرار إضافة النصوص، سيصل إلى نقطة لا يتبقى فيها أي مساحة لإضافة رسالة جديدة مع الاحتفاظ بكل ما سبق. هنا يضطر ChatGPT إلى أحد أمرين: إما تلخيص أو تجاهل الرسائل الأقدم (إذا كان النظام مصممًا على التلخيص الداخلي)، أو ببساطة إزاحة أقدم الرسائل كاملةً وإخراجها من السياق الفعال. في كلتا الحالتين، النتيجة واحدة: النموذج لم يعد “يتذكر” تلك الأجزاء القديمة حرفيًا. قد يحتفظ فقط بأفكار عامة عنها (إن تم تلخيصها داخليًا أو ذُكرت مرارًا وتكرارًا في المحادثة).
في الممارسة العملية، عندما تصبح المحادثة طويلة جدًا، قد تظهر عليك بعض المؤشرات:
- يبدأ النموذج بتقديم إجابات عامة أو أقل تحديدًا، لأنه فقد تفاصيل سابقة كانت تضفي دقة على الحوار.
- قد يكرر أسئلة سبق وأجاب عنها أو يطرح عليك معلومات كنت قد زودته بها سابقًا، مما يدل على أنها خرجت من ذاكرته المؤقتة.
- في بعض الحالات سيخبرك صراحةً: “المحادثة طويلة جدًا، يُرجى البدء بمحادثة جديدة” – خصوصًا مع النماذج الأقدم أو في حالات تجاوز صريح للحد. هذا التنبيه موجود لمنع النموذج من محاولة معالجة سياق يتجاوز طاقته.
وبخصوص الملفات الكبيرة: إذا رفعت ملفًا يتجاوز حجمه الحد بالكامل، فعلى الأرجح لن يستطيع ChatGPT قراءته كاملاً. قد يقوم بقراءة الجزء الأول فقط ثم يتوقف، أو يعتذر ويخبرك أن المدخلات كبيرة. الحل هو تجزئة الملف وإرساله على أجزاء متعددة ضمن حدود السياق، أو طلب تلخيص خارجي ثم إعطاء الملخص للنموذج. تذكّر أن الحد يشمل مجموع ما ترسله وما ينتجه النموذج أيضًا؛ لذا حتى لو تمكن من قراءة الملف الضخم، قد لا يترك ذلك مساحة كافية لإعطائك إجابة وافية بنفس الطول.
باختصار، عندما تتجاوز المدخلات أو سياق المحادثة الحد الأقصى، يتدهور أداء النموذج تدريجيًا ثم يتوقف تمامًا عن تقديم إجابات مفيدة. ستلاحظ أنه إما تجاهل تمامًا بعض الجزئيات (وهذا علامة على أنه لم يعد يراها في السياق)، أو أنه يعترف بعدم القدرة على المواصلة. الحل الأفضل عادةً: تنظيم المحادثة والملفات بحيث تبقى ضمن النطاق المسموح أو تقسيمها إلى مراحل.
أفضل 7 ممارسات للتعامل مع المحادثات الطويلة والملفات الكبيرة
للحصول على أفضل أداء من ChatGPT وتجنب مشكلة النسيان أو تجاوز الحدود، اتبع هذه الإرشادات العملية:
- قسّم الحوار إلى مواضيع أو مراحل منفصلة: إذا كان نقاشك سيتشعب إلى أكثر من موضوع رئيسي، فمن الأفضل فصل كل موضوع في محادثة جديدة. إبقاء كل محادثة مركزة قدر الإمكان يساعد النموذج على الحفاظ على التفاصيل دون إهدار المساحة على سياق قديم غير متعلق. بمجرد ملاحظة تغير محور الحديث بشكل كبير، اضغط على “محادثة جديدة” وابدأ بسياق نظيف.
- لخّص المعلومات بشكل دوري: في المحادثات الطويلة، يمكنك كل بضعة تبادلات أن تطلب من ChatGPT تلخيص ما تم مناقشته أو تلخيص النقاط المهمة التي يجب تذكرها قبل المضي قدمًا. بعد الحصول على الملخص، اعتمده كأساس وأخبر النموذج أن يستخدمه كمرجع. هذه الطريقة تضغط السياق وتزيل التفاصيل غير الضرورية، مما يسمح بتوفير مساحة لمزيد من الحوار داخل النافذة. على سبيل المثال، قل: “يرجى تلخيص ما ناقشناه حتى الآن في 5 نقاط رئيسية” ثم تابع المحادثة بناءً على ذلك.
- أعد تزويد النموذج بالمعلومات المهمة يدويًا: إذا كانت هناك معلومة أساسية تعتمد عليها (كاسم مشروع، أو قائمة متطلبات)، فلا تعتمد كليًا على أن النموذج سيتذكرها طوال الوقت. عند الانتقال لجزء جديد من الحوار يتطلب تلك المعلومة، قم بتذكير النموذج بها بإيجاز. مثلاً: “كما ذكرتُ لك سابقًا، اسم مشروعي هو X وهو تطبيق لفعل كذا…”. هذا يضمن أنها داخل نافذة السياق الحالية بدل أن تكون ربما قد سقطت منها.
- استخدم النماذج ذات نافذة السياق الأكبر عند الحاجة: إذا كنت تعلم أن مهمتك ستتطلب تحليل نصوص طويلة أو محادثة ممتدة، فاستفد من النماذج المتاحة في خطتك. في الإصدارات الحديثة من ChatGPT يمكن استخدام وضع GPT-5.4 Thinking للمهام التي تحتاج تحليلًا أعمق وسياقًا أكبر. كما توفر ميزة Projects مساحة عمل تجمع المحادثات والملفات والتعليمات في سياق واحد، وهي متاحة حاليًا لجميع المستخدمين المجانيين والمدفوعين، مع إمكانية توفر أدوات إضافية داخل المشاريع حسب الخطة المستخدمة. كذلك، لو كان لديك وصول لنموذج API بسياق موسع، ففكر في استخدامه. استخدم النموذج المناسب للمهمة لتفادي الاصطدام بحدود ضيقة.
- ارفع الملفات على أجزاء: عند التعامل مع ملفات أو وثائق ضخمة، لا ترسلها دفعة واحدة. بدلاً من ذلك، قسّم الملف إلى أجزاء أصغر (كل جزء ضمن بضع آلاف كلمة مثلاً)، وقم بإرساله جزءًا تلو الآخر مع سؤال النموذج عن كل جزء على حدة أو طلب تلخيص كل جزء ثم تلخيص الملخصات. هكذا تضمن أن كل جزء تتم معالجته دون أن يتخطى الحد. يمكنك بعد ذلك طلب تجميع الاستنتاجات من الأجزاء المختلفة.
- راقب عدد الرموز إذا كنت مطورًا أو مستخدمًا متقدمًا: عبر واجهة API توجد أدوات لحساب الرموز قبل الإرسال. حتى في واجهة ChatGPT، يمكن تقدير الطول بالكلمات/الصفحات. حاول إبقاء مدخلاتك في كل رسالة معقولة الحجم. لا تكتب مثلاً 20 صفحة في رسالة واحدة وتتوقع استجابة مثالية. كلما طالت الرسالة المفردة، ازدادت فرصة استنزافها لنصف نافذة السياق أو أكثر وحدها. إذًا من الحكمة إرسال مطالبات أكثر عددًا وأصغر حجمًا بدلاً من مطالبة واحدة عملاقة.
- استفد من ميزة “المشاريع” أو أدوات الذاكرة المضمّنة: لدى ChatGPT ميزات مثل Projects حيث يمكنك حفظ مراجع أو مصادر كجزء من مشروع مستمر. هذه لا تحتسب ضمن كل رسالة لكنها تتيح لك وللنموذج الوصول إليها عند الحاجة. أيضًا، استخدام التعليمات المخصصة (Custom Instructions) مفيد لتلقين النموذج معلومات ثابتة تريدها دائمًا دون تكرارها في كل محادثة. مثلاً، إضافة تعليمات مخصصة عن سياق عملك أو مستوى التفاصيل المرغوب سيقلل من الحاجة لإعادة تلك المعلومات في كل مرة. لكن تذكر أن هذه التعليمات المخصصة تكون مختصرة جدًا كي لا تحتل حيزًا كبيرًا من كل سياق محادثة.
باتباع هذه الممارسات، يمكنك إجراء محادثات أطول وأكثر إنتاجية مع تقليل فرصة أن يفقد ChatGPT الخيط الذي تربط به الحديث.
الخلاصة العملية
- Context Window هو ذاكرة ChatGPT المؤقتة: يتذكر النموذج آخر ما قيل ضمن حد أقصى من الرموز (الكلمات). أي شيء يتجاوز ذلك لا يكون النموذج مطلعًا عليه أثناء الرد.
- حدود السياق توسّعت مع الوقت: من بضعة آلاف رمز في GPT-3.5 إلى مئات الآلاف في النماذج الأحدث. مع ذلك، حتى أكبر النماذج لها حدود فعلية، فلا تتوقع ذاكرة لا نهائية.
- السياق ≠ الذاكرة الدائمة: النموذج لا يتذكر محادثات سابقة بين جلسات (إلا باستخدام ميزة الذاكرة). كما أن وجود نص في أعلى سجل المحادثة لا يعني أنه حاضر في ذهن النموذج حاليًا إذا طال الحوار جدًا.
- إذا بدأ النموذج ينسى، أعد تزويده بالمعلومات: عند ملاحظة إجابات غير مترابطة أو فقدان للتفاصيل، لا تتردد في توضيح ما نسيه ضمن سؤالك التالي. إعادة السياق المفقود إلى المحادثة تعيده لذاكرة النموذج.
- خطط للمحادثات الطويلة مقدمًا: قسم موضوعك، لخص نقاطك، وراقب حجم الإدخال. استخدام الاستراتيجيات الاستباقية يوفر عليك عناء فقدان المعلومات ويجعل ChatGPT أكثر فعالية في تلبية طلبك.
أخطاء شائعة حول سياق ChatGPT
- الافتراض أن ChatGPT يتذكر كل شيء دائمًا: من أكثر الأخطاء شيوعًا الاعتقاد أن النموذج لديه ذاكرة مطلقة لكل ما يُقال في المحادثة أو حتى عبر محادثات متعددة. الحقيقة أنه ينسى تدريجيًا مع تجاوز الحدود، ويبدأ كل محادثة جديدة دون معرفة بالمحادثات السابقة (ما لم تستخدم الذاكرة الشخصية).
- الخلط بين سجل المحادثة والسياق الفعلي للنموذج: يرى المستخدم قائمة طويلة من الرسائل فيظن أن النموذج مطلع عليها كلها. في الواقع النموذج قد لا “يرى” إلا آخر بضعة آلاف كلمة من هذا السجل. الاعتقاد الخاطئ هنا يؤدي لسوء فهم عندما يتصرف النموذج كأنه نسي معلومات موجودة في أعلى المحادثة.
- عدم الانتباه لوحدات القياس (الرموز مقابل الكلمات): أحيانًا يقدم المستخدم للنموذج نصوصًا ظانًا أنها قصيرة لأنها مثلاً 3000 كلمة، بينما هي في الواقع قرابة 4000 رمز وتتجاوز الحد. يجب إدراك أن النموذج يحسب الرموز (Tokens) وليس الأحرف أو الكلمات، وقد تكون الأرقام الفعلية مختلفة قليلًا عما تتصور. القاعدة التقريبية: 100 كلمة ≈ 130–150 رمز غالبًا.
- محاولة حشو كل التفاصيل في مطالبة واحدة: ظنًا بأن النموذج سيستوعب كل شيء، قد يضع المستخدم استفسارات متعددة جدًا أو نصًا ضخمًا كاملًا دفعة واحدة. هذا قد يؤدي لتجاوز الحد أو على الأقل يربك النموذج ويدفعه لتجاهل أجزاء. من الأفضل دائمًا تقسيم الطلبات وتوزيع المعلومات على رسائل متعددة.
- الاعتقاد بأن الترقية إلى Plus تعني عدم النسيان أبدًا: صحيح أن Plus يمنحك نماذج بسياق أوسع بكثير، لكن ليس صحيحًا أنه حل سحري لعدم فقدان المعلومات. حتى 128k أو 256k رمز يمكن ملؤها إذا أسرفت في النسخ واللصق دون تنظيم. بعض المستخدمين تفاجأوا أن النموذج “نسي” رغم أنهم مشتركون مدفوعون – السبب عادةً سوء استغلال للمساحة وليس خللًا في النموذج. لذا فاتباع الممارسات الجيدة يظل مطلوبًا على أي خطة.
الأسئلة الشائعة حول نافذة السياق في ChatGPT
هل Context Window تعني عدد الأحرف التي يتذكرها ChatGPT؟
نافذة السياق تُقاس بعدد الرموز النصية (tokens) وليس الأحرف تحديدًا. الرمز قد يكون حرفًا أو مجموعة حروف تشكل جزءًا من كلمة. الحد يتعلق بمجموع الرموز في المدخلات + المخرجات معًا. بالتقريب، 100 رمز تعادل 75 كلمة إنجليزية. على سبيل المثال، إذا كانت نافذة السياق 16K أو 32K أو 128K، فهذا يشير إلى عدد الرموز التي يمكن للنموذج التعامل معها ضمن نفس السياق، وليس إلى عدد الأحرف فقط. أما الأحرف فيعتمد عددها على طبيعة الكلمات (حروف اللغة العربية مثلاً تختلف عن الإنجليزية في الحساب). المهم فهم أنه حد لمجموع المدخلات والنص الناتج معًا.
لماذا يحتفظ ChatGPT بسجل المحادثة إذا كان لا يستخدمه كاملًا؟
سجل المحادثة يظهر لك كمرجع لك أنت، لتعود لأي معلومات أو أجوبة سابقة بسهولة. أما النموذج فيستخدم فقط ما يستطيع ضمن حد السياق. إبقاء السجل مفيد للمستخدم لفهم تطور الحوار، كما أنه يُستخدم في ميزة “الذاكرة” (Memory) إذا كانت مفعلة حيث قد يستشهد ChatGPT ببعض ما جاء في محادثاتك السابقة لتحسين الردود. لكن بدونه، السجل هو للأغراض التنظيمية ولا يعني ذاكرة مطلقة للنموذج. يمكنك اعتبار سجل المحادثة مثل شريط مكتوب لمراجعة الحوار، في حين أن النموذج لديه “نافذة متحركة” تطل فقط على الجزء الأخير من هذا الشريط بطول محدود.
كيف أعرف عدد الرموز المستخدمة حاليًا في محادثتي؟
واجهة ChatGPT نفسها لا تعرض عدّادًا للرموز بشكل مباشر للمستخدم. لكن هناك طرق تقريبية: يمكنك استخدام أدوات خارجية لحساب الرموز في النص الذي أدخلته (تعتمد على نفس طريقة تقسيم OpenAI). بعض المطورين يستخدمون واجهة API التي تعيد لهم معلومات عن استهلاك الرموز. كمستخدم عادي، يمكنك التخمين عبر حجم النص: كل 4–5 أحرف تقريبًا رمز واحد. أيضًا عادةً يخبرك ChatGPT إذا قاربت على الحد برسالة خطأ أو تنبيه. لو أردت الدقة، هناك مواقع وأدوات (Token counters) يمكنك نسخ المحادثة إليها لتعطيك رقمًا تقديريًا. بشكل عام، طالما محادثتك ضمن بضع صفحات نصية فلن تقترب من حدود النماذج الأحدث (التي تقاس بعشرات الصفحات).
هل يقوم ChatGPT فعلًا بتلخيص الأجزاء القديمة ذاتيًا عندما تطول المحادثة؟
غير مؤكّد رسميًا. لم تصرّح OpenAI بالتفصيل عن كيفية إدارة النموذج لسياقات تتجاوز الحد. المعروف رسميًا أنه عندما يصل الحد الأقصى لا يمكن إضافة المزيد دون حذف القديم. قد يكون هناك بعض التقنيات لتحسين الاستمرارية (مثلاً إعطاء ملخص للأجزاء المحذوفة ضمن رسائل مخفية)، لكن إن وُجدت فهي غير معلنة. في التجربة العملية، غالبًا ما يتصرّف النموذج وكأنه نسي تمامًا المعلومات خارج نافذته بدل أن يعطي معلومات ملخصة عنها، مما يرجّح أنه لا يحتفظ إلا بما داخل الحد حرفيًا. لذا عليك افتراض أنه لا يوجد تلخيص خفي يُجرى، وأن تقوم أنت بمهمة التلخيص وإعادة الإمداد إن أردت الحفاظ على مضمون القديم.
هل يمكن زيادة Context Window أكثر إذا طلبت ذلك أو دفعت أكثر؟
لا يمكن للمستخدم تغيير حجم نافذة السياق يدويًا داخل ChatGPT. لكن يمكنك اختيار خطة أو نموذج بحد سياق أكبر إذا كان ذلك متاحًا في اشتراكك.
من المهم أيضًا ملاحظة أن حدود السياق تختلف حسب النموذج والخطة، كما تختلف بين تطبيق ChatGPT للمستخدمين وبين النماذج المتاحة للمطورين عبر واجهة API. كذلك قد تختلف الحدود بين الخطط الشخصية وبين بيئات العمل المؤسسية مثل Business أو Enterprise workspaces. لذلك فإن أفضل طريقة للحصول على سياق أكبر هي اختيار نموذج أو خطة تدعم نافذة سياق أوسع.